The Enterprise AI Infrastructure Stack: From Proof of Concept to Production
Why 87% of AI Projects Fail—And How to Be in the 13% That Succeed
Prefer video? Watch the complete presentation below, or continue reading for the full deep-dive.
The Customer Problem: When Success Becomes Failure
Picture this: Your data science team just delivered an impressive proof of concept. The model predicts customer churn with 91% accuracy. Leadership is excited. The business case looks solid. You’ve got budget approval. Everyone’s ready to deploy.
Six months later, you’re sitting in a conference room explaining why the project is stalled.
Compliance flagged data sovereignty concerns you never anticipated. Infrastructure costs ballooned from $5,000 to $200,000 per month—money that wasn’t in the budget. Your team is writing custom Kubernetes operators instead of serving the model to users. The data science team has moved on to the next POC. And the business stakeholders who championed this project are wondering what happened to their AI transformation.
This is the story of the 87%.
The Data: It’s Not What You Think
Here’s what surprised me when I started researching this: It’s not technical failure. The models work. The algorithms are fine. Your data science is solid.
Multiple independent studies confirm the same pattern:
- VentureBeat (2019): 87% of data science projects never make it to production
- MIT Media Lab (2025): 95% of generative AI pilots fail to achieve measurable business impact
- Capgemini (2023): 88% of AI pilots failed to reach production
- Gartner (2019): 85% of AI projects fail
This is consistent across years, sources, and methodologies.
And here’s the punch line: According to Algorithmia’s State of Enterprise ML Survey, projects fail because of:
- Infrastructure complexity (42%) - They didn’t plan for operational complexity
- Regulatory compliance (31%) - Requirements appeared after POC approval
- Cost unpredictability (28%) - What worked in development exploded in production
- Data governance (26%) - Getting the right data with the right permissions at the right time
These are planning failures, not technical failures.
Why This Article Exists
I’ve spent 25 years building infrastructure platforms at massive scale. At AWS, I directed the largest network fabric in Amazon’s history—over 100 datacenters supporting AI workloads. At Cisco, I led the Kubernetes-based platform that powered a $1B product and supported 800+ engineers. I’ve scaled teams from 10 to 90+ engineers multiple times.
Now, as CTO at ActualyzeAI, I work with enterprises navigating exactly these challenges: getting AI from proof of concept to production without becoming part of that 87%.
This article shares battle-tested patterns from AWS, Cisco, and production AI deployments at scale. Not theory. What actually works.
The Gap Between POC and Production: Eight Dimensions You Didn’t Budget For
Let’s be brutally specific about what changes when you move from POC to production. This isn’t abstract—this is the work that someone forgot to budget when they approved the POC:
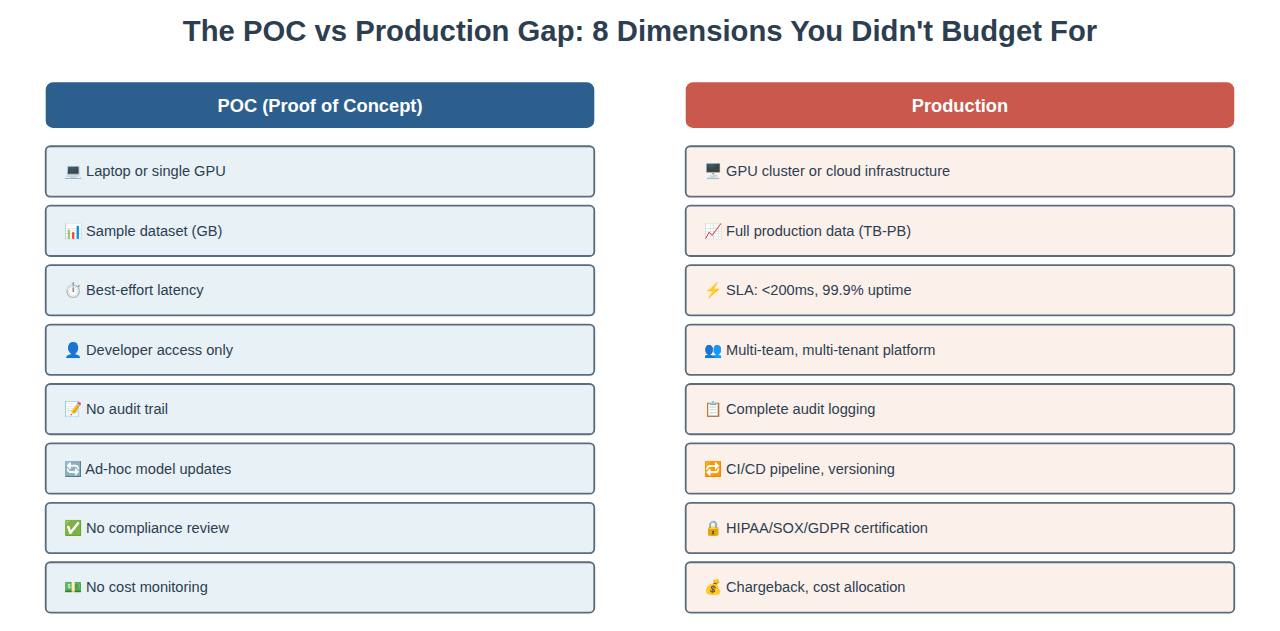
Every single line in this table represents unbudgeted work. Now multiply each line by weeks or months of effort.
The Healthcare AI Pattern: How $5K Becomes $200K
Here’s a pattern we see repeatedly in healthcare AI deployments. The names are changed, but this scenario plays out with remarkable consistency:
Months 1-3: POC Success
A regional healthcare system builds a POC that predicts patient readmission risk. 89% accuracy. Runs in the cloud for $5,000/month. Two data scientists built it in three months. The clinical team loves it. Leadership is ready to deploy across all five hospitals.
Month 4: Production Reality
Then legal and compliance review the architecture. The conversation goes like this:
- “Patient data can’t leave our data center. Full stop.”
- “This needs HIPAA compliance certification—that’s 18 technical safeguards to implement and audit.”
- “We need 99.9% uptime. Lives are at stake. No ‘best effort’ cloud SLA.”
- “It needs to serve all five hospitals with proper access controls and audit logging.”
- “And we need to explain every prediction to clinicians—this isn’t a black box.”
The Gap:
- Cost: $5,000/month → $200,000/month estimated
- Timeline: 3 months → 18 months to production
- Team: 2 data scientists → Enterprise infrastructure team required
- Scope: Single-hospital POC → Five-hospital production deployment with audit trails
The project that was “ready to deploy” in Month 3 is now an 18-month infrastructure initiative that needs CFO approval.

This composite example reflects common patterns documented in healthcare AI implementations, where HIPAA compliance requirements, data sovereignty concerns, and production infrastructure needs emerge after POC approval. Regional hospitals implementing AI-based clinical decision support consistently face these POC-to-production challenges.
This is exactly how projects end up in that 87%.
Why Enterprise AI Is Different: The Architecture Reality Check
Before we dive into solutions, let’s address a fundamental misconception: Enterprise AI is not consumer AI at scale.
When most people think “AI deployment,” they picture using ChatGPT or Claude—upload some data, get predictions, done. That works when you’re one of millions of users on a shared service optimized for convenience.
Enterprise AI is fundamentally different. You’re not a tenant on someone else’s infrastructure. You’re building production systems with requirements that would make consumer AI services impossible to operate.
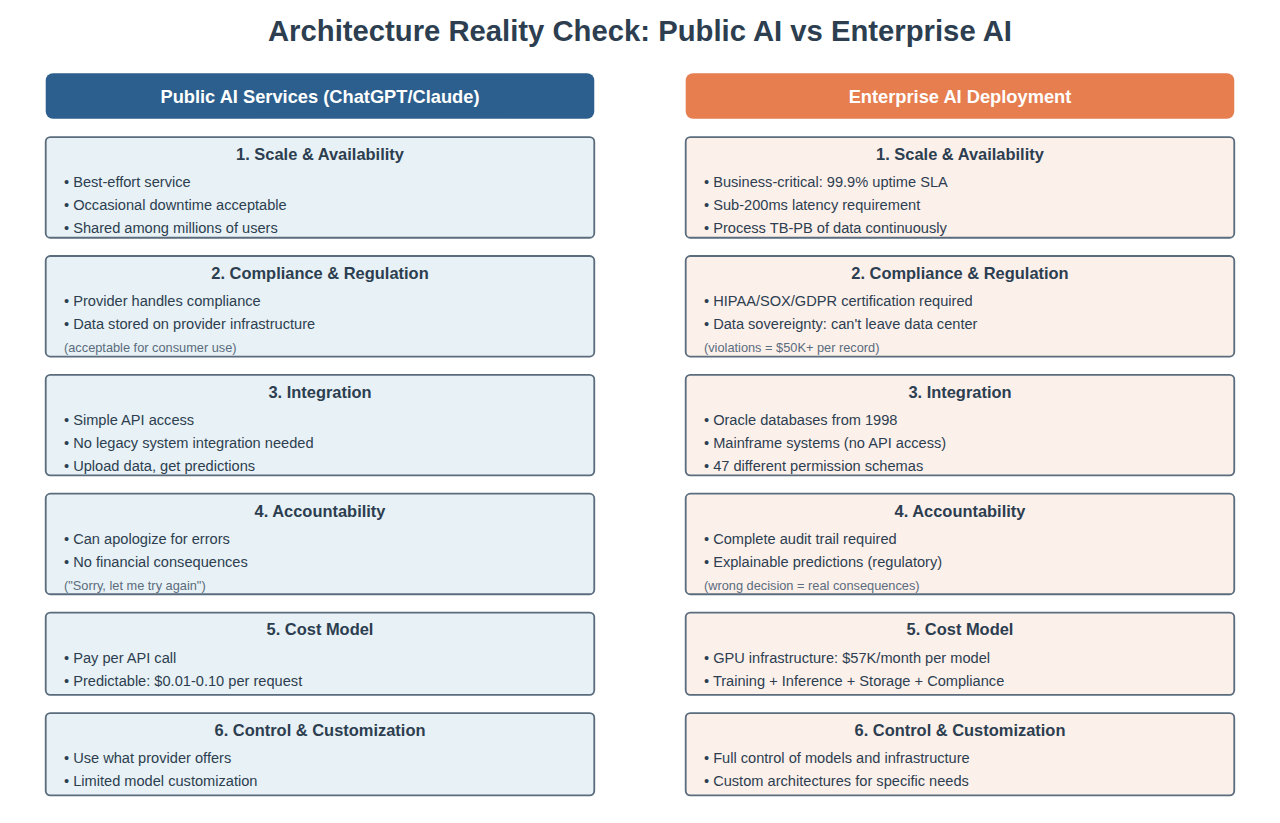
Let me walk you through what actually changes:
1. Scale: From “Best Effort” to “Business Critical”
Your data science POC served 10 users in the analytics team. They could wait 5 seconds for a prediction. If the service went down for an hour, they got coffee.
Production serves hundreds to thousands of users. Real users. Customers. Clinicians making medical decisions. Traders executing transactions. They need sub-200ms response times. They need 99.9% uptime—that’s less than 9 hours of downtime per year.
And the data volumes? Your POC used a 50GB sample dataset. Production processes terabytes to petabytes of data continuously. Every day. Forever.
2. Compliance: When “Oops” Becomes a Federal Case
Here’s where enterprises get blindsided.
If you’re in healthcare, HIPAA isn’t a suggestion—it’s 18 technical safeguards you must implement and audit. Patient data leaving your data center? That’s not a policy violation. That’s a $50,000 per violation fine from HHS.
Financial services? Sarbanes-Oxley (SOX) requires complete audit trails. Every prediction, every model version, every data access—logged, timestamped, explainable. When regulators audit you, “the algorithm said so” is not an acceptable answer.
Touching EU citizens? GDPR requires you to explain algorithmic decisions, provide data deletion guarantees, and maintain data sovereignty. The fines go up to 4% of global revenue.
These aren’t edge cases. These are table stakes for enterprise AI.
3. Integration: The Legacy System Problem Nobody Talks About
Your POC worked with clean CSV files in an S3 bucket. Beautiful.
Production needs to integrate with:
- That Oracle database from 1998 that runs critical business processes
- The mainframe system that nobody knows how to modify
- The data warehouse with 47 different permission schemas
- The legacy applications that weren’t designed for API access
And all of this has to work without breaking existing workflows that people depend on to do their jobs.
4. Accountability: When the Algorithm Makes a Mistake
Consumer AI can apologize when it hallucinates. Enterprise AI doesn’t get that luxury.
When your fraud detection model flags a legitimate transaction, a real customer can’t access their money. When your readmission risk model misses a high-risk patient, clinical outcomes suffer. When your trading algorithm makes a bad decision, real money is lost.
You need:
- Complete audit trails: Who requested the prediction? What model version? What data?
- Explainability: Why did the model make this decision? Which features mattered?
- Human oversight: Who reviews edge cases? Who approves model updates?
- Rollback capability: When a model behaves badly, how fast can you revert?
This is why infrastructure matters. You’re not running experiments. You’re running business-critical systems with regulatory requirements, integration complexity, and accountability demands that don’t exist in consumer AI.
The Impossible Choice (And the Third Way)
Here’s where most enterprise AI initiatives stall: the architecture decision meeting.
Picture the scene: You’re in a conference room. On one side, the data science team wants to move fast—”just use AWS SageMaker, we can deploy in a week.” On the other side, compliance and security are shaking their heads—”patient data can’t touch the cloud, full stop.” In the middle, the CTO is trying to figure out how to satisfy both groups without spending 18 months building infrastructure.
This is what I call “the impossible choice.” And if you haven’t faced it yet, you will.
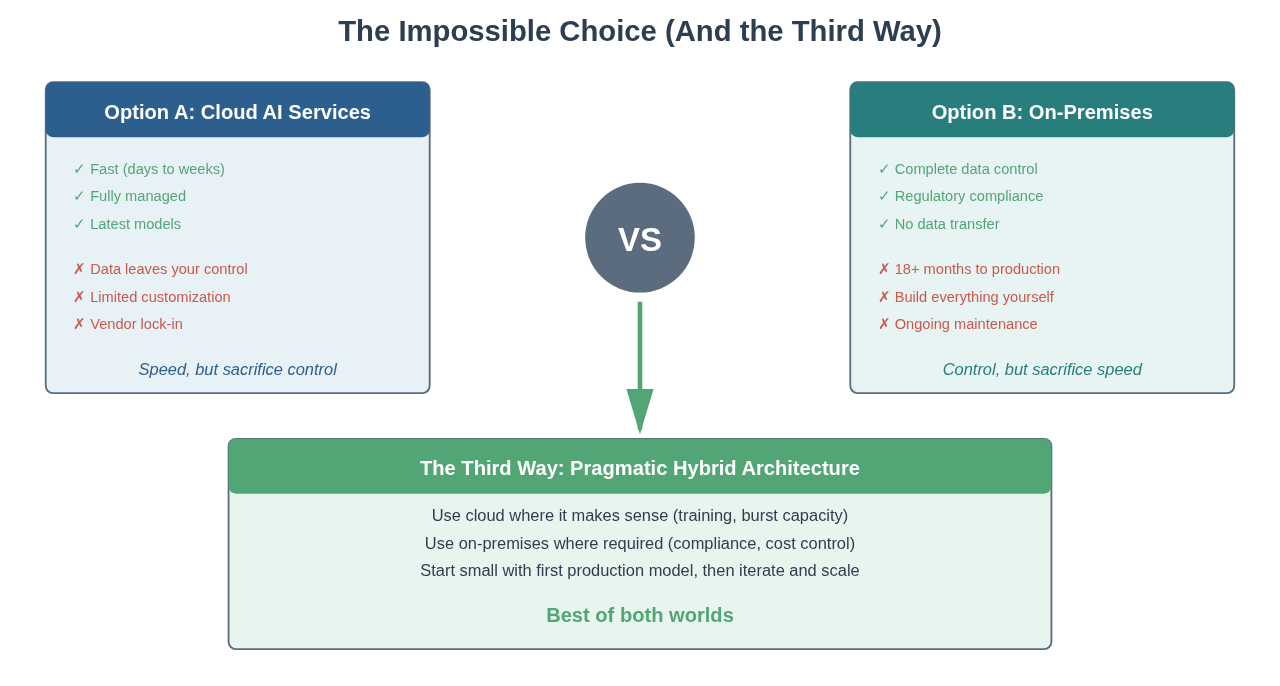
Let me walk you through both options—and why neither is acceptable as stated:
Option A: Cloud AI Services—Fast But Constrained
The Promise:
- Deploy in days to weeks, not months
- Fully managed infrastructure—no Kubernetes clusters to manage
- Latest models and features from providers investing billions in AI
- Scale elastically—handle 10 users or 10,000 users without code changes
The Reality That Kills the Deal:
- Data leaves your control: Your customer data, patient records, or financial transactions live on AWS/Azure/Google infrastructure. Compliance asks: “Which AWS datacenters? Can we audit them? What happens if there’s a breach?”
- Limited customization: You get the models and features the provider offers. Need a custom model architecture? Need specific GPU configurations? You’re constrained by what the service supports.
- Vendor lock-in: AWS SageMaker code doesn’t port cleanly to Azure ML or Google Vertex AI. Migration means rewriting pipelines, re-implementing workflows, retraining models.
I’ve watched healthcare organizations get three weeks into a SageMaker deployment before legal shut it down. “We didn’t realize patient data would leave our data center.”
Option B: On-Premises Infrastructure—Control But Slow
The Promise:
- Complete data control—every bit stays in your data center
- Meet any regulatory requirement—HIPAA, SOX, GDPR, you name it
- No data transfer costs—no egress fees, no bandwidth limits
- True portability—you own the stack, you control the architecture
The Reality That Kills Momentum:
- 18+ months to production: By the time you procure hardware, deploy Kubernetes, configure GPU scheduling, implement CI/CD, and get through security review… 18 months is optimistic. I’ve seen it take 24+ months.
- Build everything yourself: Model serving infrastructure, experiment tracking, feature stores, monitoring, alerting, cost allocation—you’re implementing from scratch or integrating a dozen open-source tools.
- Ongoing maintenance burden: Kubernetes upgrades, security patches, GPU driver updates, certificate renewals—you now own a platform team’s worth of operational overhead.
I’ve watched startups spend their entire Series A funding on infrastructure before deploying a single production model. The business ran out of runway.
The Dilemma: Speed vs. Control
Most organizations look at these options and feel stuck. Executives say “we need both—fast deployment AND compliance.” Engineers reply “pick one.”
The Third Way: Pragmatic Hybrid Architecture
But here’s what I learned building infrastructure at AWS and Cisco: You don’t have to choose one or the other. You choose deliberately for each workload based on your specific constraints.
The pattern that works in production:
Use cloud where it makes sense:
- Training: You need burst capacity. Spin up 32 GPUs for 48 hours to retrain your fraud detection model, then shut them down. Cloud gives you this without maintaining idle hardware.
- Experimentation: Data scientists trying new model architectures benefit from cloud flexibility. Let them experiment fast.
- Non-sensitive workloads: If the data isn’t regulated and latency isn’t critical, cloud may be the right trade-off.
Use on-premises where required:
- Compliance-critical inference: If HIPAA says data can’t leave your data center, then inference stays on-prem. Non-negotiable.
- Low-latency workloads: If you need sub-50ms response times for fraud detection, cloud round-trips won’t cut it. On-prem inference is the answer.
- High-volume inference: Processing 5 million predictions per day? On-premises hardware amortizes cost faster than paying per-inference to a cloud provider.
Start small with your first production model, then iterate and scale:
- Month 1-6: Deploy your first model with the minimum viable infrastructure
- Month 7-12: Learn from real usage patterns, optimize based on actual costs and performance
- Month 13+: Scale to additional models and teams based on proven patterns
The key insight: There is no perfect architecture. There are only trade-offs you choose deliberately based on your constraints, your risks, and your goals. The 87% who fail try to find the perfect answer. The 13% who succeed make deliberate trade-offs and ship production models.
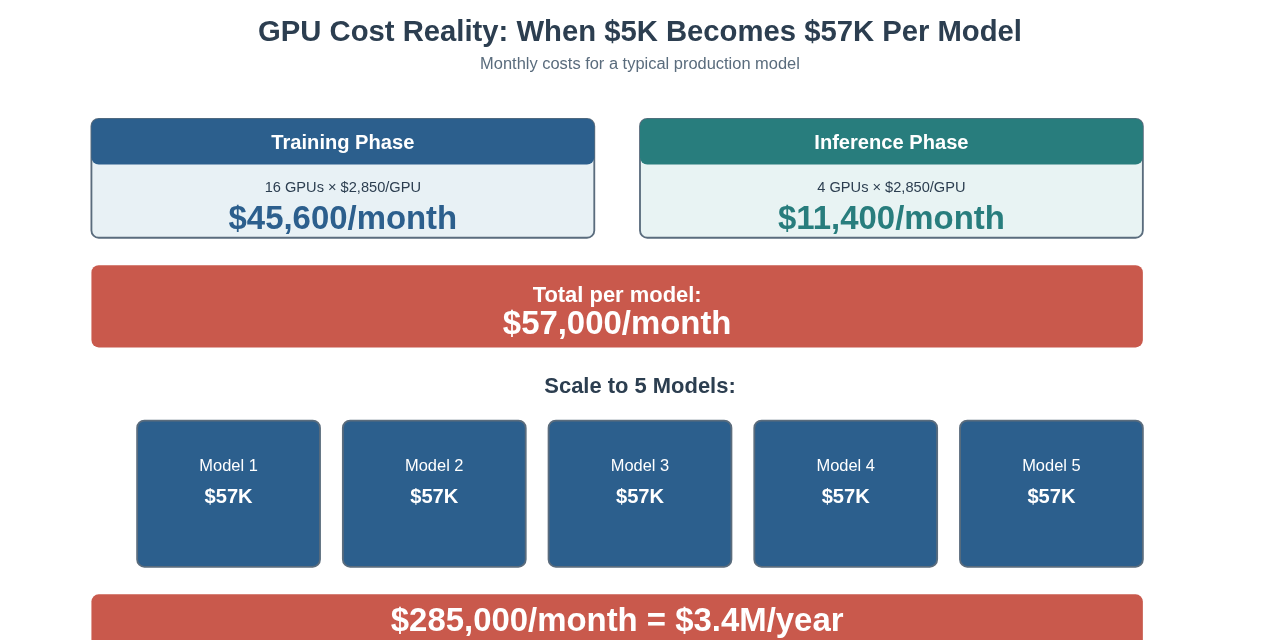
The Cost Reality: When $5K Becomes $57K Per Model
Now let’s talk about the moment that kills more AI projects than any technical challenge: the cost conversation with the CFO.
Here’s how it usually goes:
Month 3: You present the POC results. 91% accuracy. Leadership loves it. Budget approved: $5,000/month based on POC costs. Everyone’s excited to deploy.
Month 6: You’re back in the CFO’s office explaining why the production budget needs to be $57,000/month. Per model. And you need to deploy five models.
The CFO looks at you and asks: “How did $5,000 become $285,000?”
Let me show you exactly how this happens—with real numbers, not hand-waving.
The GPU Economics Nobody Explains During the POC
An NVIDIA A100 GPU—the workhorse for enterprise AI—costs between $3.67 and $4.10 per hour on major cloud providers:
- AWS p4d.24xlarge: $4.10/hour per GPU
- Azure ND96amsr A100 v4: $4.10/hour per GPU
- GCP A100 40GB: $3.67/hour per GPU
Running 24/7? That’s approximately $2,700-3,000 per GPU per month. Just sitting there, serving predictions or training models.
Your POC probably used one GPU, maybe running part-time. Let’s say $5,000/month total—includes the GPU, some CPU instances, storage, and networking. Reasonable for a proof of concept.
The Production Math That Catches Everyone Off Guard
Now let’s do the math for a typical production model—emphasis on typical, not worst-case:
Training Phase Requirements:
- 16 GPUs running in parallel (needed for reasonable training time on production data volumes)
- × $2,850 average cost per GPU per month
- = $45,600/month just for training infrastructure
Why 16 GPUs? Because training on your full production dataset (terabytes, not the gigabyte sample from your POC) takes days or weeks on a single GPU. Production teams retrain weekly or monthly as new data arrives and model performance drifts. You need parallel GPU training to make this feasible.
Inference Phase Requirements:
- 4 GPUs running 24/7 for production serving (needed for redundancy, load balancing, and meeting latency SLAs)
- × $2,850 average cost per GPU per month
- = $11,400/month for inference infrastructure
Why 4 GPUs for inference? Because production demands high availability. You need:
- 2 GPUs active-active for load balancing (handle traffic spikes, maintain low latency)
- 1 GPU for canary deployments (test new model versions on 10% of traffic)
- 1 GPU for redundancy (when one fails or needs maintenance)
Total cost per model: $57,000/month
That $5,000/month POC is now $57,000/month in production. That’s not a 10% increase. That’s not a 2x increase. That’s an 11x increase.
The CFO Moment: Scaling to Multiple Models
Now here’s where it gets really uncomfortable.
Your POC was one model: customer churn prediction. Great. But the business case you presented to get funding showed AI creating value across multiple use cases:
- Customer churn prediction (the POC)
- Fraud detection (the CISO wants this)
- Recommendation engine (the VP of Product is counting on this)
- Customer service chatbot (the COO is already announcing this externally)
- Risk scoring for underwriting (compliance is mandating this)
Five models. All “approved” based on the POC cost of $5,000/month.
The actual math:
- 5 models × $57,000/month = $285,000/month
- Annual cost: $3.4 million
This is the moment CFOs start asking: “Why wasn’t this in the original business case?”
And the honest answer is: Because nobody did the production cost modeling before approving the POC.
The Hidden Variables That Make This Worse
Those numbers above? On-demand pricing. Real-world costs have more variables:
Cost reduction opportunities:
- Spot instances: 50-70% cheaper, but can be terminated with 2 minutes notice (not viable for production inference)
- Reserved capacity: 30-50% cheaper with 1-3 year commitments (better for steady-state workloads)
- Alternative providers: Some cloud providers offer A100s as low as $0.40/hour, though with different SLAs and compliance certifications
Cost increase factors:
- Compliance requirements: HIPAA-compliant infrastructure costs 20-30% more (dedicated instances, enhanced monitoring, audit logging)
- High availability: Multi-region deployments for disaster recovery double infrastructure costs
- Data transfer: Moving terabytes of training data incurs egress fees ($0.08-0.12 per GB on major clouds)
The bottom line: GPU costs are the single largest line item in your production AI budget. They’re also the most surprising, because they scale non-linearly from POC to production.
This cost shock kills projects. Not because the budget doesn’t exist somewhere in the company, but because nobody planned for it when the POC was approved. The CFO approved $60K annually. You need $3.4M annually. That’s not a budget variance. That’s a different project.
The successful projects? They model production costs before the POC starts. They get CFO buy-in on realistic numbers before the engineering work begins. They budget for 5-10x the POC cost and call it success when actual costs come in at 6-7x.
This is planning, not technical execution. But it’s what separates the 87% who fail from the 13% who succeed.
Three Infrastructure Patterns That Work
Here’s the good news: proven patterns exist for managing this complexity and cost. These aren’t theoretical. They’re battle-tested at AWS, Cisco, and enterprises running production AI at scale.
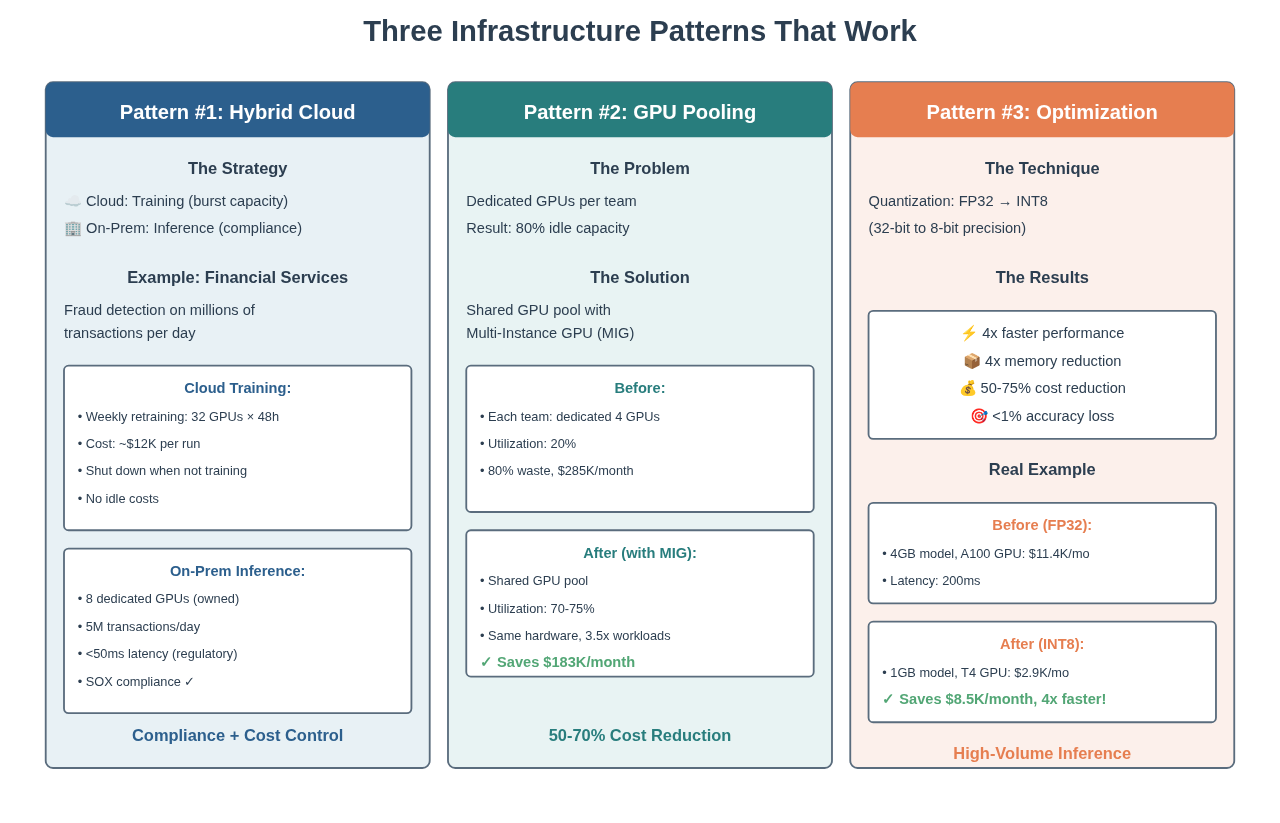
Pattern #1: Hybrid Cloud Architecture—Best of Both Worlds
The pattern: Use cloud for training (you need burst capacity). Use on-premises for inference (meet compliance, control costs).
Real-World Example: Financial Services
A major bank runs fraud detection on millions of credit card transactions daily. Here’s their architecture:
Cloud (Training):
- Retrain models weekly on new fraud patterns
- Burst to 32 GPUs for 48 hours
- Cost: ~$12,000 per training run
- Shut down when not training—no idle costs
On-Premises (Inference):
- Production inference serving 24/7
- 8 dedicated GPUs (owned hardware)
- Process 5 million transactions per day
- Sub-50ms latency requirement (regulatory)
- SOX compliance—data never leaves their data center
Why this works:
Cloud training provides burst capacity without maintaining idle GPU infrastructure. You only pay when you’re actually training.
On-premises inference amortizes hardware costs across millions of daily transactions while meeting sub-50ms latency requirements that are impossible with cloud round-trips. For high-volume inference (1M+ requests/day), on-prem hardware ROI is typically 12-18 months.
The trade-off: You’re managing two environments. But you get regulatory compliance, cost control, and the flexibility to retrain quickly.
Pattern #2: GPU Pooling and Multi-Tenancy—Stop Wasting 80% of Your GPU Budget
Here’s a pattern that will make your CFO happy.
The Problem:
Traditional approach: Give each team dedicated GPUs. Marketing gets 4 GPUs. Finance gets 4 GPUs. Product gets 4 GPUs.
Result? Each team uses their GPUs about 20% of the time. 80% idle. You’re paying for capacity you’re not using.
The Solution:
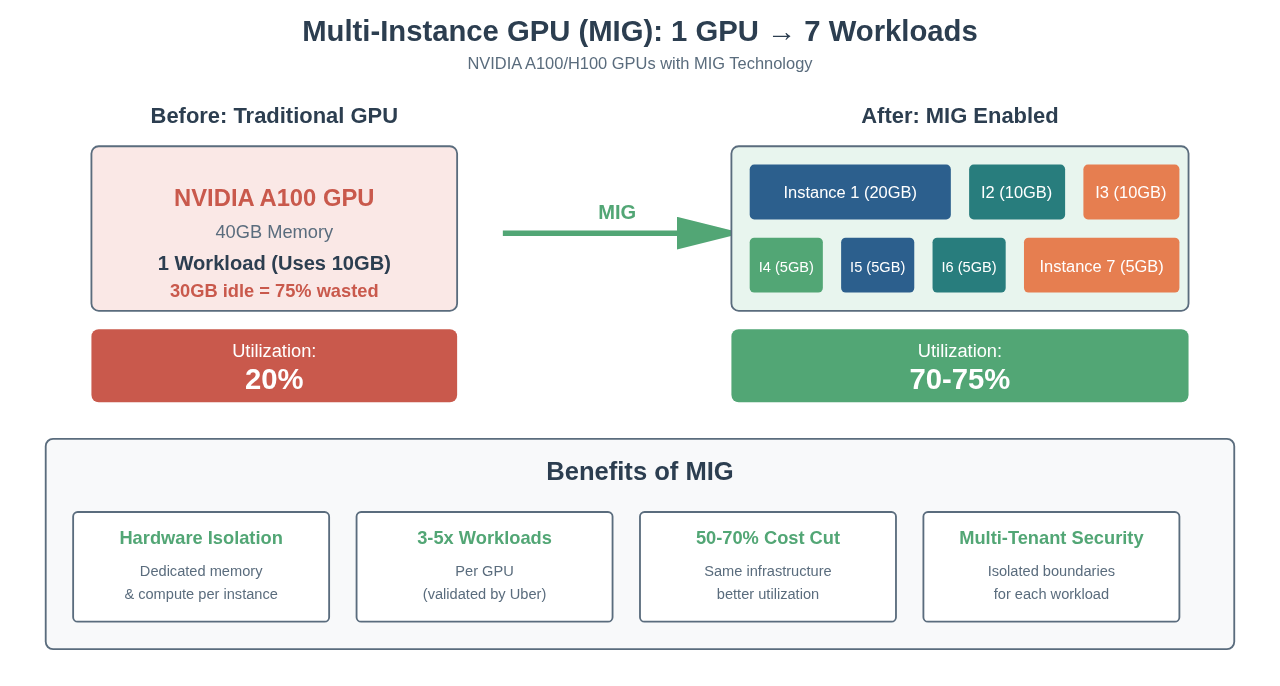
Create a shared GPU pool. Multi-Instance GPU (MIG) on NVIDIA A100s lets you divide one physical GPU into up to 7 independent instances. Each instance has dedicated memory and compute. Each can serve a different model or team.
Real Results from Production Deployments:
- Utilization: 20% → 70-75% average
- Cost reduction: 50-70% for the same workloads
- Same hardware, same capabilities
Production Validation:
Uber achieved 3-5x more workloads per GPU with MIG. Snap reported significant utilization improvements across their infrastructure.
The Math:
Start with $285,000/month for 100 GPUs at 20% utilization. Implement GPU pooling and MIG. Same 100 GPUs now run at 70% utilization—serving 3.5x more workloads.
Result: You just saved $183,000/month without buying a single new GPU. Same infrastructure, better utilization.
Why this works:
Most inference workloads don’t need a full GPU. A fraud detection model might need 10GB of GPU memory. A recommendation engine might need 20GB. MIG gives you isolated slices with security boundaries—critical for multi-tenant deployments.
Pattern #3: Model Optimization—Get 4x Faster Performance and 75% Cost Reduction
This one surprises people: You can make your models faster and cheaper at the same time.
The Technique: Quantization
Quantization converts your model from 32-bit floating point (FP32) to 8-bit integer precision (INT8).
Think of it like this: Instead of storing every number with 32 bits of precision, you use 8 bits. For most inference tasks, you don’t need that level of precision.
The Results:
- 4x faster performance (INT8 vs FP32)
- 4x memory footprint reduction—fit 4 models where you fit 1 before
- 50-75% inference cost reduction—use smaller/cheaper GPU instances
- Minimal accuracy loss: <1% typical for most models
Real Example:
A recommendation engine serving 10 million predictions per day:
Before quantization:
- FP32 model: 4GB memory
- Requires A100 GPU instances: $11,400/month
- 200ms average latency
After quantization:
- INT8 model: 1GB memory
- Can run on T4 GPU instances: $2,900/month
- 50ms average latency (4x faster!)
- Accuracy: 94.2% → 93.9% (0.3% drop)
Savings: $8,500/month per model. 4x faster. Nearly identical accuracy.
When this works: Most production inference workloads. Computer vision, recommendation engines, NLP classification. When this doesn’t work: Applications requiring extreme numerical precision.
These three patterns aren’t theoretical. They’re proven at AWS, Cisco, and enterprises running production AI at scale today.
Decision Framework: Three Questions That Matter More Than Technology
Stop trying to find the “perfect architecture.” It doesn’t exist.
Here’s what separates the 87% who fail from the 13% who succeed: The 87% chose technology first. The 13% answered three questions first:
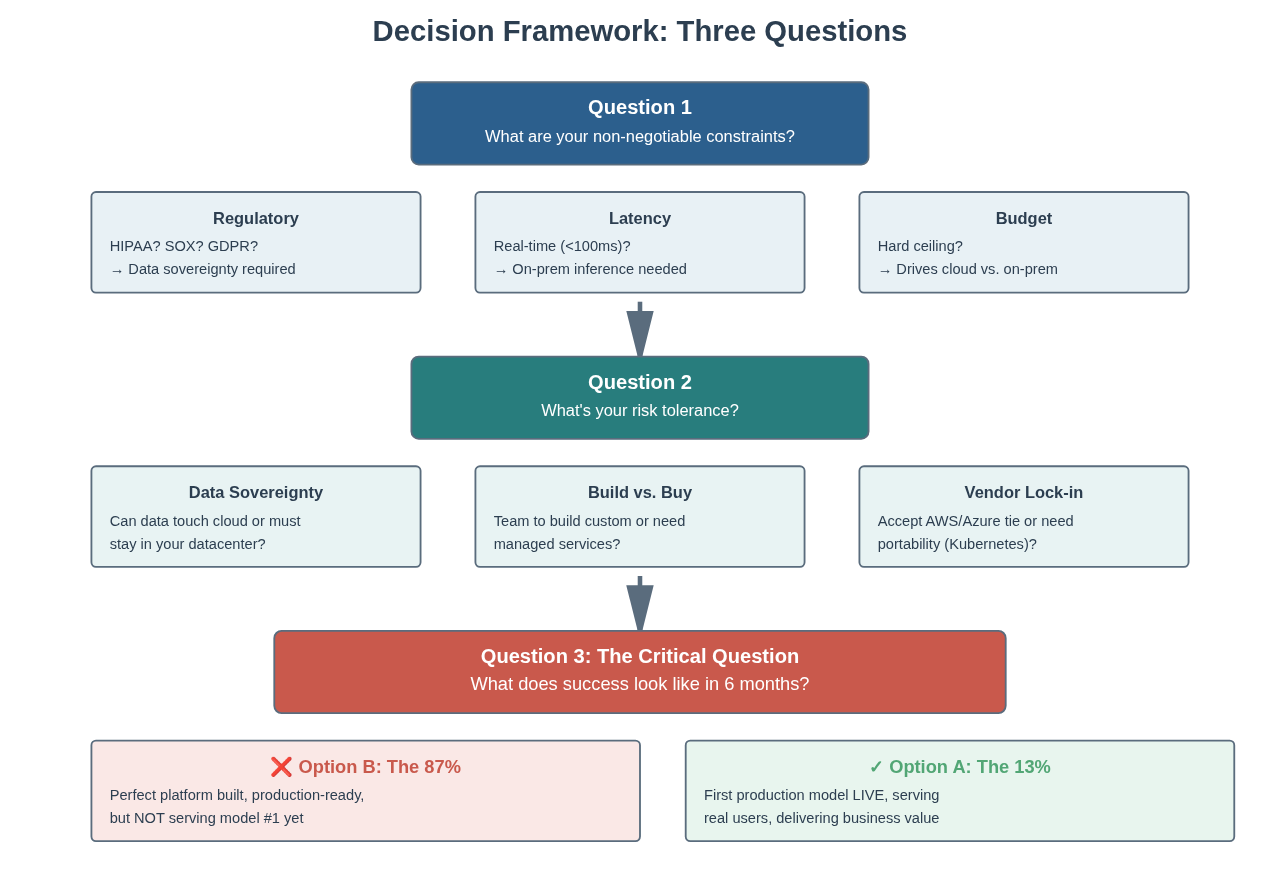
These three questions matter more than any technology decision:
1. What are your non-negotiable constraints?
These are the things that will kill your project if you get them wrong:
- Regulatory: Are you in healthcare (HIPAA), financial services (SOX), or touching EU citizens (GDPR)? If yes, data sovereignty isn’t negotiable.
- Latency: Do you need real-time response (<100ms) or is batch processing acceptable? Real-time requires different architecture.
- Cost: What’s your budget ceiling? Not your wish-list budget—your actual approved budget.
2. What’s your risk tolerance?
No judgment here—different organizations have different appetites for risk:
- Data sovereignty vs. convenience: Can patient data touch AWS, or must it stay in your data center?
- Build vs. buy: Do you have the team to build custom infrastructure, or do you need managed services?
- Vendor lock-in: Can you accept being tied to AWS/Azure/Google for speed, or do you need portability?
3. What does success look like in 6 months?
This is the critical question. Be honest:
- Option A: First production model serving real users, with monitoring, with actual business value delivered?
- Option B: Perfect platform built, production-ready, but not serving model #1 yet?
The trap is spending 18 months building the perfect platform before deploying model #1.
The 13% who succeed? They choose Option A. They get their first production model running in 6 months. They learn from real usage. They optimize based on actual data. They iterate. They scale.
The 87% who fail? They choose Option B. They spend 18 months building infrastructure. The business requirements change. Leadership changes. Budgets get cut. The project dies before model #1 goes live.
Success is getting your first production model running in 6 months, not building the perfect platform in 18 months.
Architecture Patterns by Industry: How Constraints Drive Decisions
Remember when I said there’s no perfect architecture? Let me show you what this looks like in practice.
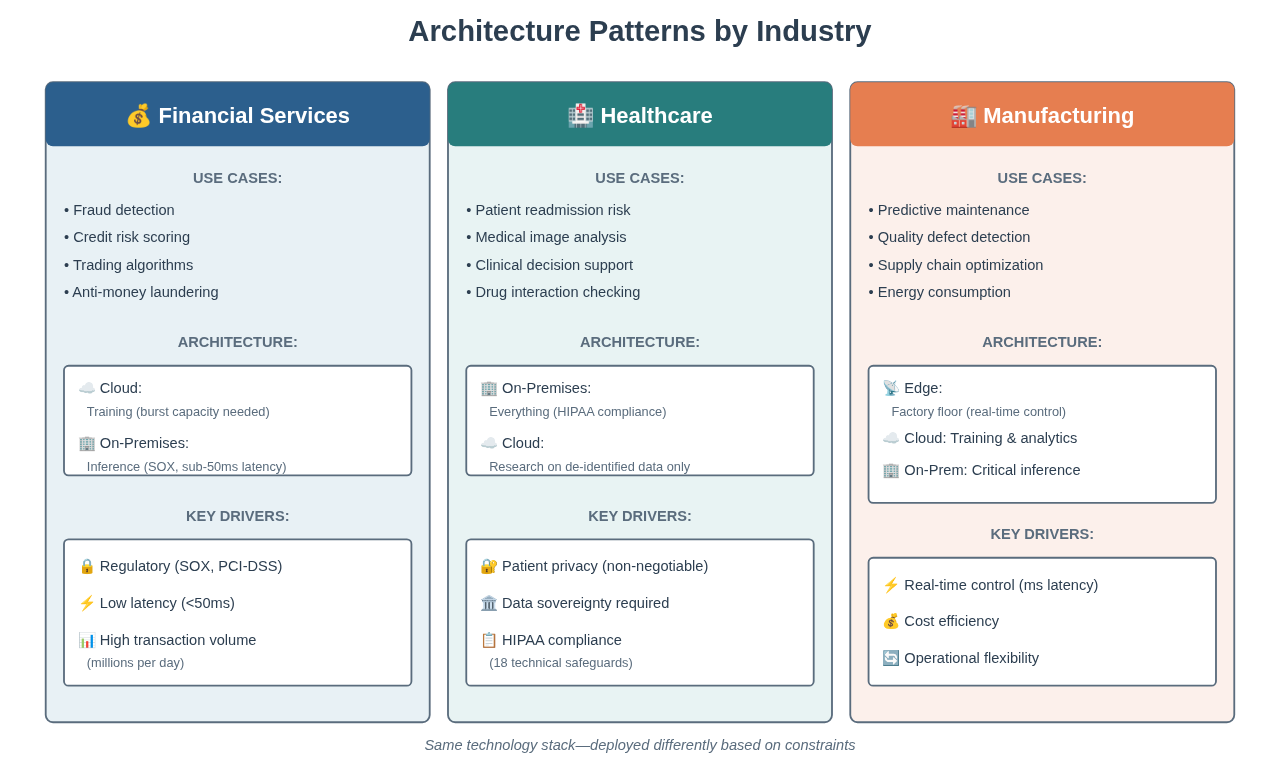
Let me walk you through three real-world patterns, explaining why each industry makes the choices they do:
Financial Services: Hybrid Architecture—Speed Where It Matters, Control Where It Counts
A major bank runs fraud detection on 5 million credit card transactions per day. Here’s how they architected their deployment:
Use Cases They’re Running:
- Real-time fraud detection (flag suspicious transactions in <50ms)
- Credit risk scoring (underwriting decisions)
- Trading algorithms (market prediction models)
- Anti-money laundering monitoring (regulatory requirement)
Their Architecture Choice:
- Cloud: Training infrastructure - Burst to 32 GPUs for 48 hours weekly to retrain fraud models on new patterns
- On-Premises: Inference serving - 8 dedicated GPUs running 24/7 in their data center
Why This Architecture?
Let me explain the decision-making process:
Why cloud for training?
- Fraud patterns evolve constantly. They retrain models weekly with new transaction data.
- Training requires 32 GPUs for 48 hours per week. Owning 32 GPUs means paying for them 24/7 while using them 29% of the time (48 hours out of 168 hours per week).
- Cloud cost: ~$12,000 per training run. Monthly: ~$48,000.
- On-prem equivalent: 32 GPUs × $2,850/month = $91,200/month sitting mostly idle.
- Savings: $43,200/month by using cloud for training.
Why on-premises for inference?
- SOX compliance requires complete audit trails—every prediction, every data access, logged and retained for 7 years.
- Latency is non-negotiable: When a customer swipes their card, the fraud check must complete in under 50 milliseconds. Cloud round-trip latency alone is 20-30ms before you even run the model. On-prem inference: sub-10ms.
- Volume economics: 5 million transactions/day × 365 days = 1.825 billion predictions/year. At cloud API pricing ($0.10/1000 predictions), that’s $182,500/year. On-prem hardware (8 GPUs for redundancy and load balancing): $273,600/year. But the hardware lasts 3-4 years, so amortized cost is $68,400-91,200/year.
- ROI: On-prem inference pays for itself in 18 months.
The Trade-Off They Accept: They’re managing two environments—cloud for training, on-prem for inference. That means two deployment pipelines, two sets of credentials, two security reviews. But they get regulatory compliance, sub-50ms latency, and cost efficiency at volume.
This is a deliberate trade-off based on their specific constraints.
Healthcare: On-Premises—When Data Sovereignty Is Non-Negotiable
A regional healthcare system with five hospitals runs patient readmission risk prediction. Their architecture looks completely different:
Use Cases They’re Running:
- Patient readmission risk prediction (predict which patients are likely to return within 30 days)
- Medical image analysis (radiology AI assistance)
- Clinical decision support (flag potential drug interactions, suggest treatment protocols)
- Drug interaction checking (real-time alerts when physicians prescribe medications)
Their Architecture Choice:
- On-Premises: Everything - Training, inference, data storage, model management—all in their data center
- Cloud: Research only, with de-identified data - Data scientists can experiment on de-identified datasets in the cloud, but nothing touches production
Why This Architecture?
The decision is simpler than financial services, but more absolute:
Why on-premises for everything?
- HIPAA compliance is non-negotiable: Patient data cannot leave their data center without Business Associate Agreements (BAAs), encryption in transit and at rest, and audit trails. Moving patient data to AWS for model training? Legal says no. Full stop.
- Patient privacy isn’t a trade-off: One HIPAA violation can cost $50,000 per patient record exposed. A breach affecting 10,000 patient records? $500 million fine, plus lawsuits, plus reputation damage. No amount of “faster deployment” justifies that risk.
- 99.9% uptime is lives, not SLAs: When clinical decision support goes down, physicians can’t see drug interaction warnings. That’s not a service outage. That’s a patient safety issue.
The Cost They Pay:
- Slower deployment: 18 months from POC to production (hardware procurement, security review, compliance audit)
- Higher upfront capital: $500K-1M for GPU infrastructure, on-prem Kubernetes cluster, networking, storage
- Ongoing maintenance: Platform team of 4-6 engineers maintaining infrastructure, security patches, compliance audits
Why They Accept This Cost: Because the alternative—cloud deployment with patient data—isn’t legally or ethically acceptable. HIPAA data sovereignty is a hard constraint, not a preference.
The One Exception: Their research team can use cloud for experimentation—but only with de-identified data that’s been stripped of all Protected Health Information (PHI). Even then, it never touches production systems.
This is what “non-negotiable constraints” look like in practice.
Manufacturing: Hybrid + Edge—Real-Time Control Meets Cloud Analytics
A large automotive manufacturer runs predictive maintenance AI on factory equipment. Their architecture is the most complex:
Use Cases They’re Running:
- Predictive maintenance (predict equipment failure 24-48 hours in advance)
- Quality defect detection (identify manufacturing defects in real-time on production line)
- Supply chain optimization (predict delays, optimize inventory)
- Energy consumption optimization (reduce factory power costs)
Their Architecture Choice:
- Edge: Factory floor - Small GPU-enabled edge devices running inference in real-time on production lines
- On-Premises: Critical inference - Data center-based Kubernetes cluster for plant-wide analytics
- Cloud: Training and batch analytics - Train models on historical data, run supply chain optimization
Why This Architecture?
This is the most interesting one because they’re balancing three different deployment models:
Why edge for factory floor?
- Real-time control demands: When quality defect detection spots a problem on the assembly line, it needs to trigger an alert or shut down the line immediately—within 50-100 milliseconds. Sending data to a cloud endpoint (200+ms round-trip) or even an on-prem data center (20-30ms round-trip) is too slow.
- Network reliability: Factory floor networks experience intermittent connectivity. Edge devices must function even when disconnected from the cloud or data center.
- Data volume: Production lines generate terabytes of sensor data daily. Sending all that data to the cloud for processing isn’t feasible (bandwidth costs, latency, storage).
Why on-premises for critical inference?
- Plant-wide analytics: Optimizing energy consumption or managing inventory across multiple production lines requires centralized processing that’s too complex for edge devices.
- Cost control: Running continuous inference on equipment across 50 production lines is cheaper on owned hardware than paying cloud API costs.
Why cloud for training?
- Historical data analysis: Training predictive maintenance models requires analyzing years of equipment sensor data. Cloud provides the burst capacity for these training jobs without maintaining idle GPUs on-prem.
- Supply chain optimization: This workload analyzes external data (shipping delays, supplier data, market conditions) that’s already in the cloud. Cheaper to process it there than move it on-prem.
The Trade-Off They Accept: Managing three deployment tiers (edge, on-prem, cloud) means three times the operational complexity—different deployment tools, different monitoring, different security models. But they get real-time control where it matters (edge), cost efficiency for steady-state workloads (on-prem), and flexibility for variable workloads (cloud).
The Pattern: Constraints Drive Architecture, Not Preferences
Same technology stack (Kubernetes, GPUs, ML pipelines). Same types of models (classification, prediction, optimization). Completely different deployments.
Financial services chooses hybrid because SOX compliance and sub-50ms latency requirements make on-prem inference mandatory, but variable training workloads favor cloud burst capacity.
Healthcare chooses on-premises because HIPAA data sovereignty is non-negotiable. No trade-offs. No exceptions.
Manufacturing chooses hybrid + edge because real-time control on the factory floor requires edge computing, but historical analysis and training benefit from cloud scalability.
The lesson: Stop looking for the “right” architecture. Start identifying your non-negotiable constraints. Then design deliberately around those constraints.
The Technical Foundation: Kubernetes for AI
Now let’s get technical. You’ve decided on hybrid architecture based on your constraints. You understand the cost models. You have CFO approval. Great.
Now the question is: How do you actually build this?
The answer for most enterprises: Kubernetes.
But before you roll your eyes and think “not another Kubernetes pitch,” let me explain why Kubernetes became the de facto standard for enterprise AI infrastructure—and what it actually solves.
Why Kubernetes for AI Infrastructure? (And Why Your Data Scientists Might Resist)
Here’s a conversation I’ve had more than once:
Data Scientist: “Why do we need Kubernetes? I can deploy my model to AWS Lambda in 10 minutes.”
Platform Engineer: “Can you deploy it to our on-prem data center? Can you handle 100,000 requests per second? Can you share GPUs across teams? Can you roll back when the model breaks?”
Data Scientist: “…I’ll learn Kubernetes.”
Kubernetes solves four problems that become critical at enterprise scale:
1. Container Orchestration: Solving “It Works on My Machine”
Your data scientist built a model in Python 3.10 with TensorFlow 2.15, CUDA 12.1, and 17 specific PyPI packages at exact versions. It works perfectly on their laptop.
Now deploy it to production. Different Python version. Different CUDA driver. Missing dependencies. “It worked on my machine” becomes “it’s broken in production.”
Containers solve this: Package the model, Python runtime, all dependencies, and CUDA libraries into a single container image. That exact image runs identically on the data scientist’s laptop, in the staging cluster, and in production. Same behavior everywhere.
Kubernetes orchestrates containers: Deploy, update, scale, and monitor containers across hundreds of servers. When a container crashes, Kubernetes restarts it automatically. When load increases, Kubernetes scales to more replicas. When you deploy a new model version, Kubernetes rolls it out gradually and rolls back automatically if errors spike.
2. Abstraction Layer: Avoiding the $2M Vendor Lock-In Mistake
I watched a fintech company spend $2 million rewriting their AI infrastructure because they built everything on AWS SageMaker-specific APIs. When they needed to deploy on-premises for compliance, nothing was portable. Complete rewrite.
Kubernetes is your portability layer. Write your deployment once. Run it on:
- AWS (EKS - Elastic Kubernetes Service)
- Azure (AKS - Azure Kubernetes Service)
- Google Cloud (GKE - Google Kubernetes Engine)
- On-premises (your own data center with bare metal servers or VMware)
- Hybrid (some workloads in cloud, some on-prem, same deployment tooling)
Same YAML configs. Same kubectl commands. Same monitoring. Same deployment patterns.
This is how you make the “third way” hybrid architecture actually work—deploy training to cloud, deploy inference on-prem, use the same infrastructure tooling for both.
3. Built for Scale: From 10 Users to 10,000 Users Without Rewriting
Your POC served 10 users. They could wait 5 seconds for a prediction. One GPU was plenty.
Production serves 10,000 users. They need sub-200ms response. You need 50 GPU instances for redundancy and load balancing.
Kubernetes handles scaling automatically:
Horizontal Pod Autoscaling (HPA): Define a target (e.g., “keep CPU at 70%”). Kubernetes monitors metrics and automatically scales your model serving pods from 2 replicas to 20 replicas when load increases. Scales back down when load decreases. No manual intervention.
Cluster Autoscaling: When you need more GPUs than you have, Kubernetes requests more nodes from your cloud provider (or alerts you to provision more on-prem hardware). Infrastructure scales with demand.
Load Balancing: Kubernetes distributes inference requests across all your model replicas automatically. One replica crashes? Traffic routes around it. New replica comes online? Traffic routes to it immediately.
Self-Healing: Container crashes? Kubernetes restarts it. Node fails? Kubernetes reschedules all pods to healthy nodes. Network partitions? Kubernetes maintains quorum and keeps serving requests.
4. Industry Standard: Standing on the Shoulders of Giants
Here’s what you don’t have to build if you use Kubernetes:
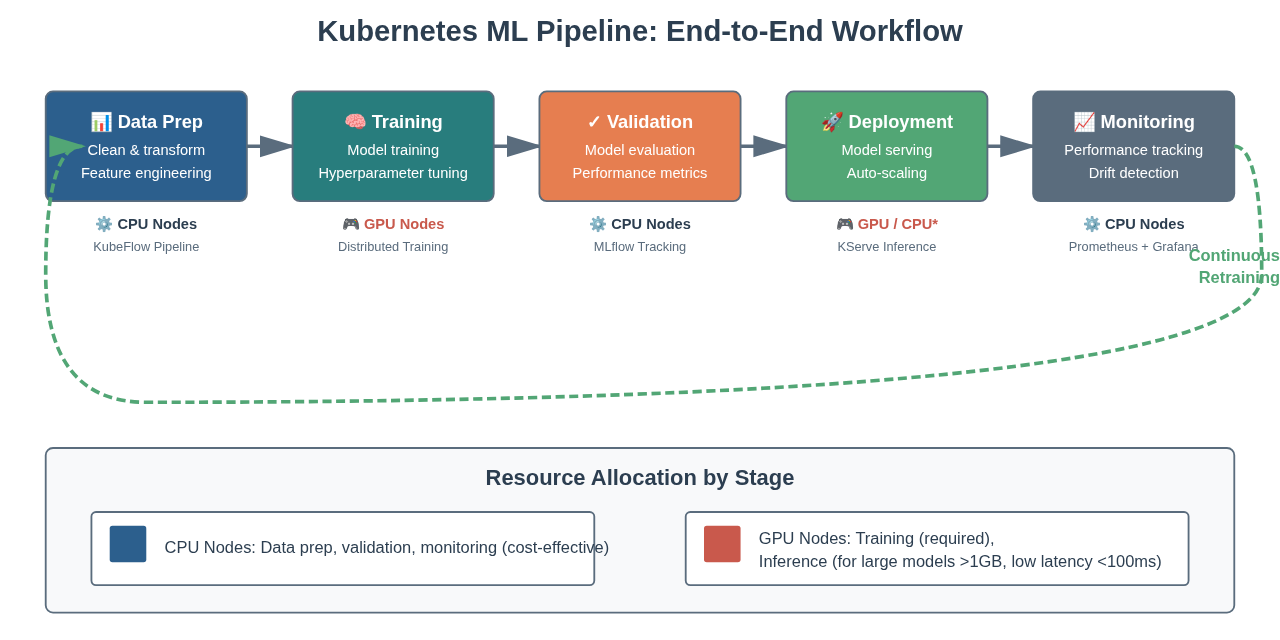
Model Serving: KServe gives you production-grade model serving in less than 20 lines of YAML. Auto-scaling, canary deployments, A/B testing, multi-framework support (TensorFlow, PyTorch, scikit-learn, XGBoost). Already solved.
ML Pipelines: KubeFlow orchestrates end-to-end ML workflows—data prep, training, validation, deployment. Already solved.
Experiment Tracking: MLflow integrates with Kubernetes to track experiments, log metrics, version models. Already solved.
Monitoring: Prometheus and Grafana are the standard for Kubernetes monitoring. Pre-built dashboards for GPU utilization, model latency, request throughput. Already solved.
Cost Allocation: Kubecost tracks resource usage by namespace (team), labels (project), and workload. Automatic chargeback reports. Already solved.
The Kubernetes Learning Curve (Is Worth It)
Yes, Kubernetes has a learning curve. Yes, your data scientists will complain about YAML. Yes, it’s more complex than clicking “deploy” in a cloud console.
But here’s what you get in return:
- Portability: Not locked into one cloud provider
- Scalability: Handle 10x growth without rewriting
- Reliability: Production-grade high availability and self-healing
- Cost efficiency: Share infrastructure across teams, track costs precisely
- Ecosystem: Every ML tool integrates with it
The 87% who fail? They avoid Kubernetes complexity and build custom infrastructure that breaks at scale.
The 13% who succeed? They invest 2-3 months learning Kubernetes and get infrastructure that scales to billions of predictions.
GPU vs. CPU: Making the Expensive Decision
For Training: Use GPUs. Period. Unless you have very small models, training on CPU takes weeks instead of hours. Production models need 8-32 GPUs for reasonable training time.
For Inference: It depends. This is where you can save money.
Use GPU inference when:
- Models are large (>1GB)
- Real-time response required
- High throughput needed (thousands of requests/second)
- Sub-100ms latency required
Use CPU inference when:
- Models are small (<100MB)
- Batch processing acceptable
- Cost is primary concern
- Requests are occasional
Cost Example:
- GPU inference: $0.10/1000 requests
- CPU inference: $0.01/1000 requests
For 1 million requests/day: $36K/year (GPU) vs. $3.6K/year (CPU). Wrong choice wastes $32K/year per model.
GPU Scheduling in Kubernetes: How to Not Waste $100K on Idle Hardware
Here’s a problem that costs enterprises hundreds of thousands of dollars annually: GPUs sitting idle because nobody can find them.
The scenario: Your data science team needs a GPU to train a model. You have 50 GPUs in your cluster. 30 of them are idle right now. But the data scientist can’t tell which nodes have available GPUs, can’t request one programmatically, and ends up waiting for someone from infrastructure to manually provision access.
Meanwhile, those 30 idle GPUs are costing $85,500/month ($2,850 per GPU × 30 GPUs). Idle. Doing nothing.
Kubernetes GPU scheduling solves this. Treat GPUs as schedulable resources, just like CPU and memory. Request a GPU declaratively, and Kubernetes finds an available one, schedules your workload there, and deallocates it when done.
Here’s what this looks like in practice—a real Kubernetes pod configuration requesting GPU resources:
apiVersion: v1
kind: Pod
metadata:
name: gpu-inference-pod
spec:
containers:
- name: model-server
image: my-model:v1
resources:
requests:
nvidia.com/gpu: 1 # Request 1 GPU
limits:
nvidia.com/gpu: 1 # Limit to 1 GPU
nodeSelector:
gpu-type: nvidia-a100 # Select A100 nodes
tolerations:
- key: nvidia.com/gpu
operator: Exists
What’s happening here:
resources.requests: “I need 1 GPU to run.” Kubernetes finds a node with an available GPU and schedules the pod there.
resources.limits: “Don’t give me more than 1 GPU.” Prevents a single workload from accidentally consuming all GPUs.
nodeSelector: “I specifically need an A100 GPU, not a T4 or V100.” You might have different GPU types for different workloads—A100s for training, cheaper T4s for inference. This ensures you get the right hardware.
tolerations: GPU nodes typically have “taints” to prevent regular (non-GPU) workloads from accidentally scheduling there and wasting expensive GPU capacity. Tolerations say “I’m a GPU workload, I’m allowed on GPU nodes.”
Under the hood, you need two components:
-
NVIDIA GPU Operator: Installs GPU drivers, CUDA libraries, and container runtime on every GPU node. This used to be manual—install drivers on each server, configure CUDA, update when new versions released. The GPU Operator automates all of it.
-
Device Plugin: Exposes GPUs as countable, schedulable resources to Kubernetes. Without this, Kubernetes doesn’t know which nodes have GPUs or how many are available.
The result: Kubernetes treats GPUs like first-class resources. Your data scientist requests “I need 1 GPU.” Kubernetes finds one, schedules the workload, runs it, and frees the GPU when done. No manual provisioning. No idle capacity. No wasted $85K/month.
Model Serving with KServe
Here’s how simple production model serving can be:
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: sklearn-iris
spec:
predictor:
sklearn:
storageUri: "gs://my-bucket/model"
resources:
requests:
cpu: "100m"
memory: "1Gi"
limits:
cpu: "1"
memory: "2Gi"
This simple configuration gives you:
- Auto-scaling (0 to N replicas based on load)
- Canary deployments (A/B testing)
- Model versioning (multiple versions live simultaneously)
- Integrated monitoring (latency, throughput, errors)
Production-grade model serving in less than 20 lines of configuration.
Multi-Tenancy: Sharing Infrastructure Safely (Without Teams Killing Each Other’s Models)
Here’s a problem that emerges at every multi-team enterprise: Team conflicts over shared infrastructure.
The scenario without multi-tenancy:
Monday morning: The finance team deploys a new fraud detection model. It consumes all 50 GPUs in the cluster for training.
The marketing team’s recommendation engine—serving 100,000 requests per hour to the production website—gets evicted from GPUs to make room for finance’s training job.
The website breaks. Customers can’t see product recommendations. Revenue drops. The CMO calls the CTO: “Why is marketing’s production model down?”
The CTO calls the VP of Engineering: “Why did finance kill marketing’s production workload?”
Meanwhile, the research team is wondering why their experiment hasn’t scheduled for 3 days—turns out finance and marketing are monopolizing all capacity.
This is the multi-tenancy problem. And it kills more AI initiatives than most technical failures.
Why Multi-Tenancy? The Business Case
Multi-tenancy solves four problems simultaneously:
1. Cost Efficiency: $285K → $100K Monthly
Without multi-tenancy: Each team gets dedicated infrastructure. Finance gets 20 GPUs. Marketing gets 20 GPUs. Research gets 10 GPUs. Total: 50 GPUs × $2,850 = $142,500/month.
Problem? Finance uses their 20 GPUs 30% of the time. Marketing uses theirs 40% of the time. Research uses theirs 15% of the time. Average utilization across all teams: 28%. You’re paying $142,500/month but using only $40,000 worth of capacity.
With multi-tenancy: Shared pool of 50 GPUs with quotas per team. Finance is allowed up to 20 GPUs when available, but when they’re not using them, marketing or research can use that capacity. Average utilization: 70%. Same 50 GPUs, same $142,500/month, but you’re using $100,000 worth of capacity.
Result: 2.5x more work on the same hardware budget.
2. Resource Utilization: From 20% to 70-75%
Industry average GPU utilization without sharing: 20-30%. With multi-tenancy and Multi-Instance GPU (MIG): 50-75% achievable.
Translation: You can run 3x more models on the same infrastructure. Or reduce infrastructure costs by 60% for the same workload.
3. Centralized Management: One Platform Team, Not Five
Without multi-tenancy: Each team manages their own cluster. Five teams = five Kubernetes clusters = five sets of monitoring, five sets of security policies, five sets of upgrades.
With multi-tenancy: One shared cluster. One platform team. One upgrade cycle. One security policy. One monitoring stack.
Savings: 4 fewer platform teams. If a platform team costs $800K/year (4 engineers × $200K fully loaded), that’s $3.2M annual savings.
4. Fair Sharing: Quotas Prevent the “Wild West”
Without quotas: First come, first served. Finance’s training job at 3 AM Monday consumes all GPUs. Marketing’s production inference gets evicted. Website breaks.
With quotas: Finance is limited to maximum 20 GPUs, even when 50 are available. Marketing’s production workloads are guaranteed minimum 15 GPUs. Research gets remainder.
Result: Production workloads are protected. Teams can’t accidentally (or intentionally) monopolize shared resources.
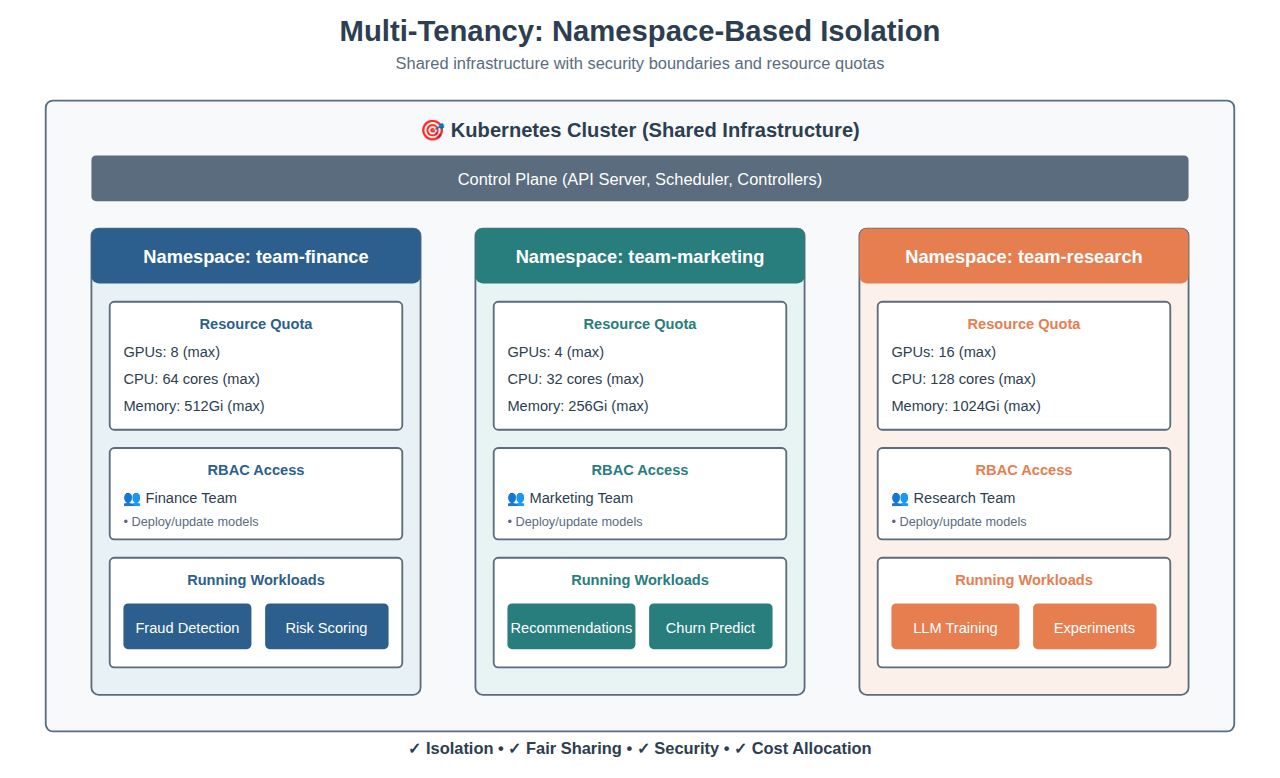
The Pattern: Namespace-Based Isolation
Here’s how it works—each team gets their own Kubernetes namespace (think of it as a virtual cluster within the physical cluster):
# Namespace
apiVersion: v1
kind: Namespace
metadata:
name: team-finance
# Resource Quota
apiVersion: v1
kind: ResourceQuota
metadata:
name: team-finance-quota
spec:
hard:
requests.nvidia.com/gpu: "8"
requests.cpu: "64"
requests.memory: "512Gi"
pods: "100"
# RBAC - RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: finance-team-binding
subjects:
- kind: Group
name: finance-team
roleRef:
kind: Role
name: namespace-admin
What you get:
- Isolation: Teams can’t interfere with each other
- Fairness: Resource quotas prevent hogging
- Security: RBAC ensures proper access control
- Cost allocation: Track usage by namespace for chargeback
Cost Allocation and Chargeback: Making Teams Care About GPU Waste
Here’s a conversation that happens at every enterprise running shared AI infrastructure:
CFO: “We’re spending $200,000 a month on GPU infrastructure. Which teams are using this?”
VP Engineering: “Um… all of them?”
CFO: “How much is each team using?”
VP Engineering: “I don’t know. It’s shared infrastructure.”
CFO: “So we can’t allocate costs to business units. We can’t do chargeback. We can’t tell which teams are wasting resources and which are efficient. Fix this.”
This is the cost allocation problem. And it matters more than you think.
Why Cost Allocation Matters: The “Tragedy of the Commons”
When infrastructure is free to teams (i.e., centrally funded with no chargeback), teams have zero incentive to optimize. Finance trains a model on 32 GPUs for a week straight. Marketing runs inference on GPUs when CPUs would work fine. Research spins up experiments and forgets to shut them down.
Nobody’s being malicious. They’re just optimizing for their goals (fast experiments, low latency, quick results) instead of cost. Because cost isn’t their problem.
The solution: Track costs by team. Implement chargeback. Suddenly teams care about optimization.
How It Works: Track Everything by Namespace
Kubernetes namespaces make this simple. Every workload runs in a namespace. Every namespace belongs to a team. Track resource consumption by namespace, and you automatically have per-team cost data.
Track these metrics:
- GPU hours consumed (most expensive—$3-4 per GPU per hour)
- CPU hours consumed (cheaper but adds up at scale)
- Storage used (models, datasets, training checkpoints)
- Network egress (moving data out of your data center or cloud region)
Example Monthly Report
Here’s an example monthly report from a 50-GPU shared cluster:
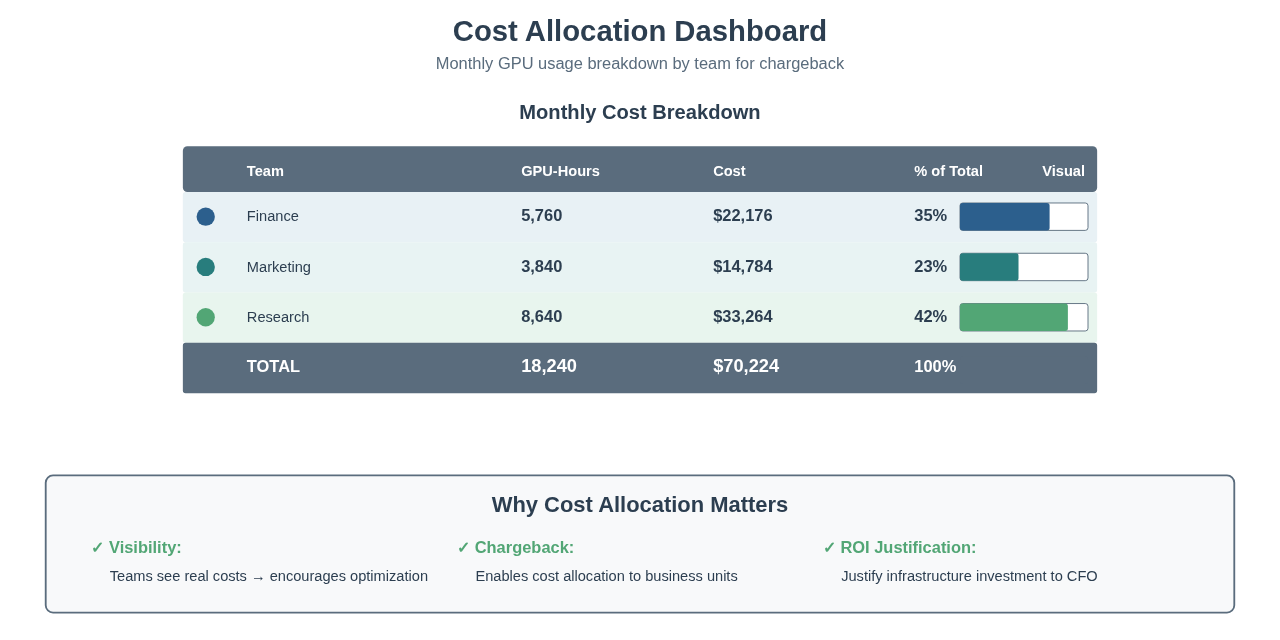
(Cost based on average A100 GPU cost of $3.85/hour—calculated as the mean of AWS $4.10/hr, Azure $4.10/hr, and GCP $3.67/hr on-demand pricing)*
What this tells you:
Finance team: 5,760 GPU-hours, $22K, 35% of total. They’re running fraud detection training weekly (48 hours × 4 weeks × 30 GPUs = 5,760 hours). This is expected and justified by business value.
Marketing team: 3,840 GPU-hours, $14.8K, 23% of total. They’re running recommendation engine inference on GPUs 24/7 (4 GPUs × 24 hours × 30 days = 2,880 hours) plus some experimentation. Question: Could inference run on CPUs instead? Potential savings: $10K/month.
Research team: 8,640 GPU-hours, $33.3K, 42% of total. This is the highest cost. Are they getting equivalent business value? Or are experiments running idle? Follow-up needed.
What Happens When Teams See Their Costs
Real outcome from a Fortune 500 I worked with:
Month 1: Shared infrastructure, no chargeback. Monthly cost: $180,000. No complaints.
Month 2: Implemented cost allocation. Published team-by-team report. Sent to VPs with budget responsibility.
Month 3: Marketing optimized their recommendation engine—moved inference from GPUs to CPUs. Savings: $11,000/month. Research implemented auto-shutdown for idle experiments. Savings: $18,000/month.
Month 4: Total cluster cost: $151,000. Same workloads. 16% cost reduction just because teams could see their usage.
Why this worked: Once teams had budget ownership, they optimized. Not because anyone forced them—because now it was their budget, their P&L impact.
Tools That Make This Automatic
Kubecost and OpenCost (open-source) integrate with Kubernetes to:
- Automatically track resource usage by namespace, label, pod, and team
- Generate monthly cost reports with breakdowns
- Alert when costs spike (e.g., “Research team GPU usage up 300% this week”)
- Predict monthly costs based on current usage trends
Cloud provider tools: If you’re using managed Kubernetes (EKS, AKS, GKE), built-in cost allocation tools integrate directly with cloud billing. Track Kubernetes costs alongside other cloud services.
Making This Work: Three Rules
1. Charge back to business units, not engineering teams
Don’t charge the engineering managers—they don’t control budgets. Charge the VP of Marketing for marketing workloads, VP of Finance for fraud detection, etc. Put it in their P&L. Now they care about optimization.
2. Start with showback (reporting) before chargeback (billing)
Month 1-3: Just publish cost reports. No actual budget transfers. Let teams see their usage and optimize voluntarily.
Month 4+: Implement actual chargeback. Transfer costs to business unit budgets.
This gives teams time to optimize before it hits their P&L.
3. Make the reports actionable
Don’t just show “$22K spent by Finance team.” Show:
- “Finance: $22K, 5,760 GPU-hours, fraud detection training (expected)”
- “Marketing: $14.8K, 3,840 GPU-hours, 70% inference (consider CPU migration, potential $10K/month savings)”
- “Research: $33.3K, 8,640 GPU-hours, 35% from idle experiments (implement auto-shutdown, potential $12K/month savings)”
Give teams specific actions, not just numbers.
The bottom line: Cost allocation turns “shared infrastructure is expensive” into “our team needs to optimize.” That shift in accountability saves more money than any technical optimization.
The ML Tools Ecosystem
You’re not building from scratch. Proven tools integrate with Kubernetes:
Pipelines & Orchestration:
- KubeFlow - Complete ML pipelines
- Argo Workflows - Flexible orchestration
- Apache Airflow - Data pipeline integration
Model Serving:
- KServe - Kubernetes-native standard
- NVIDIA Triton - High-performance serving
- TorchServe - PyTorch models
- TensorFlow Serving - TensorFlow models
Experiment Tracking & Registry:
- MLflow - Experiment tracking, model registry
- Weights & Biases - Advanced tracking
- DVC - Data version control
Monitoring:
- Prometheus + Grafana - Metrics and dashboards
- ELK Stack - Logging
- DataDog - Commercial support
This is the power of the ecosystem: assembling proven components instead of building from scratch.
Four Key Takeaways: How to Be in the 13%
1. Let’s Be Clear: Enterprise AI Is Technically Hard
GPU orchestration. Distributed training. Model serving at scale. Multi-tenancy. Compliance integration. This is complex infrastructure work.
Don’t let anyone tell you it’s trivial. It’s not. Anyone who says “just deploy it to the cloud” has never deployed enterprise AI in a regulated industry.
But—and this is critical—it’s solvable. Proven patterns exist. AWS, Cisco, Google, Microsoft, and enterprises running production AI at scale have figured this out. You don’t have to invent it from scratch.
2. But Here’s The Surprise: Most Failures Are Non-Technical
87% fail on governance, compliance, and cost—things you can plan for from day 1.
The models work. The algorithms are fine. The data science is solid.
Projects fail because:
- Nobody asked compliance about HIPAA requirements before the POC
- Nobody modeled the real infrastructure costs before getting budget approval
- Nobody thought about multi-tenant access controls before promising it to five business units
- Nobody planned for 99.9% uptime SLAs before signing the contract
The lesson: Plan from day 1. Don’t say “we’ll figure out compliance after the POC works.” That’s the guaranteed path to the 87%.
3. Kubernetes Provides the Abstraction Layer
Kubernetes makes hybrid cloud, portable workloads, and battle-tested patterns for scale possible.
This means you’re not inventing infrastructure from scratch. You’re assembling proven components: KServe for model serving, KubeFlow for pipelines, Prometheus for monitoring, MIG for GPU sharing.
The hard infrastructure problems are already solved. Your job is to assemble them for your specific constraints.
4. Start Small, Iterate, Scale—Not the Other Way Around
Get your first production model running in 6 months, not your perfect platform in 18 months.
Deploy one model. Measure real usage. Learn what actually matters—not what you thought would matter. Optimize based on data. Then scale.
The 87% who fail? They try to build the perfect platform first. The 13% who succeed? They ship model #1, learn from it, and iterate.
Getting Started: Next Steps
If you’re starting your enterprise AI journey:
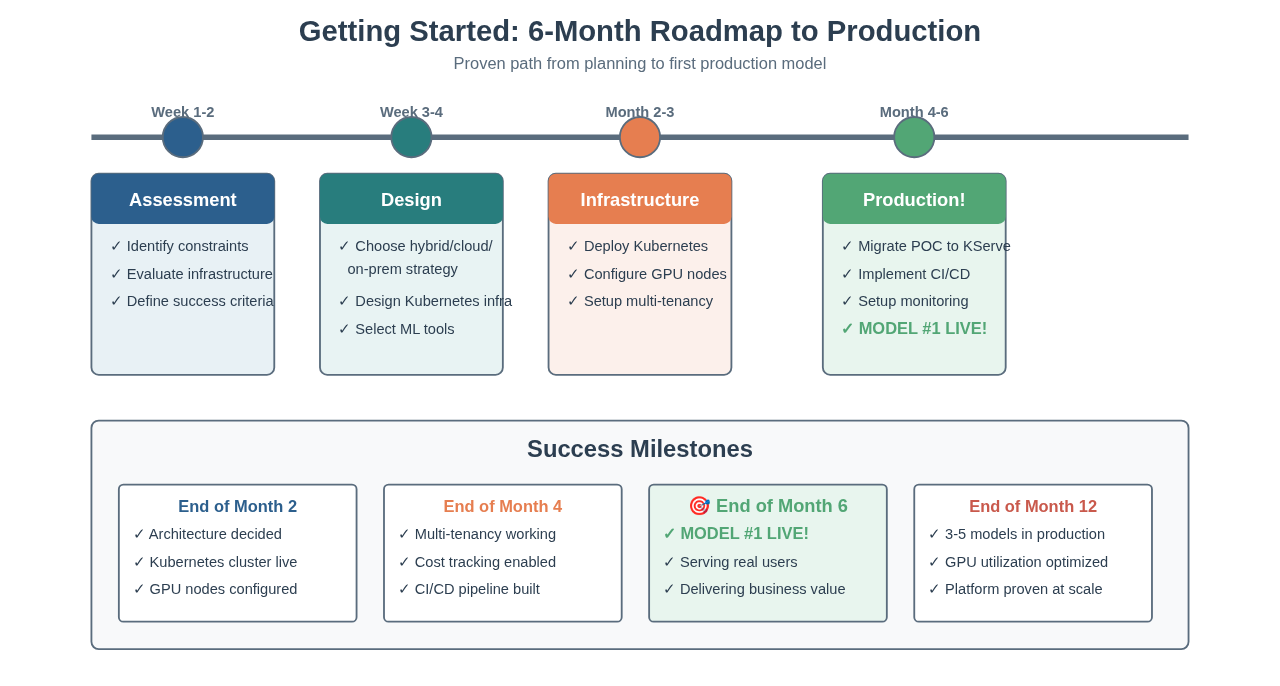
Week 1-2: Assessment
- Identify non-negotiable constraints (regulatory, latency, cost)
- Evaluate current infrastructure capabilities
- Define success criteria for first production model
Week 3-4: Architecture Design
- Choose hybrid/cloud/on-prem strategy based on constraints
- Design Kubernetes infrastructure
- Select ML tools (KServe, MLflow, monitoring)
Month 2-3: Infrastructure Setup
- Deploy Kubernetes cluster (managed or self-hosted)
- Configure GPU nodes and scheduling
- Set up multi-tenancy with namespaces and quotas
- Implement cost tracking
Month 4-6: First Production Model
- Migrate POC to production-grade serving (KServe)
- Implement CI/CD pipeline
- Set up monitoring and alerting
- Deploy with proper access controls and compliance
Month 7+: Iterate and Scale
- Measure actual costs and utilization
- Optimize GPU allocation (MIG, CPU inference where appropriate)
- Deploy additional models
- Refine based on real-world learnings
The Real Secret: There Is No Perfect Architecture
Here’s what separates the 13% who succeed from the 87% who fail:
The 87% who fail:
- They looked for the “perfect architecture”
- They built POCs without thinking about production
- They discovered compliance requirements after approval
- They watched costs explode without planning
- They spent 18 months building infrastructure before deploying model #1
- They let circumstances choose for them
The 13% who succeed:
- They understood their constraints before the POC
- They planned for production infrastructure from day 1
- They made deliberate architecture trade-offs based on their specific constraints
- They started small: first production model in 6 months
- They learned from real usage, optimized, and scaled
- They chose deliberately
There is no perfect architecture.
There are only trade-offs you choose deliberately based on your constraints, your risks, and your goals.
Financial services chooses hybrid (cloud training, on-prem inference) because of SOX compliance and sub-50ms latency requirements.
Healthcare chooses on-premises because HIPAA data sovereignty is non-negotiable.
Manufacturing chooses hybrid + edge because they need real-time control on the factory floor.
Same technology stack—Kubernetes, GPUs, ML pipelines—deployed completely differently based on each industry’s deliberate choices.
The choice is yours. Will you be in the 87% who fail, or the 13% who succeed?
Join the Community
The Tampa Bay Enterprise AI Community brings together CTOs, platform engineers, compliance officers, and business leaders navigating these exact challenges.
Monthly Meetups:
- Real-world case studies from regulated industries
- Technical deep-dives on infrastructure patterns
- Strategic discussions on architecture trade-offs
- Peer learning from leaders facing similar challenges
Connect:
- Slack: join.slack.com/t/enterpriseaicommunity
- Meetup: meetup.com/enterprise-ai-community
- LinkedIn: /company/tampabay-enterprise-ai
Next Event: November 14, 2025 Topic: AI Compliance Framework for Regulated Industries
Additional Resources
Documentation:
Regulatory Frameworks:
Industry Reports:
About the Author
David Lapsley, Ph.D., is CTO of ActualyzeAI and has spent 25+ years building infrastructure platforms at scale. Previously Director of Network Fabric Controllers at AWS (largest network fabric in Amazon history) and Director at Cisco (DNA Center Maglev Platform, $1B run rate). He specializes in helping enterprises navigate the infrastructure challenges that cause 87% of AI projects to fail.
Contact: david@actualyze.ai
This blog post is based on the October 2025 Tampa Bay Enterprise AI Community inaugural meetup presentation. Recording and slide deck available at community resources.